
News
April, 2026Our paper “Design First, Code Later: Aesthetically Pleasing Template-Free Slides Generation” was accepted by the ACL 2026 Findings!
February, 2025Our paper “Multi-LLM-Agents Debate-Performance, Efficiency, and Scaling Challenges” was accepted by the Blogpost track of ICLR 2025!
August, 2024My homepage is online!
... see all News
Hello👋, I’m Zhiyao!
🌱I am currently pursuing a Ph.D. in Artificial Intelligence at Northwestern Polytechnical University, with a research focus on multi-agent systems driven by large language models (LLMs) and vision-language models (VLMs). I completed my undergraduate degree in Information Security at Northwestern Polytechnical University(NWPU) in June 2024.
💡I’m particularly interested in developing robust and practical AI systems capable of effectively managing diverse and dynamic scenarios. This involves enhancing the adaptability, efficiency, and reliability of AI-driven solutions to tackle complex real-world problems.
👯Beyond academics, I hold a black belt in Taekwondo and have achieved the highest level in electronic keyboard. Whether in research or personal life, I enjoy challenges and believe in bringing curiosity and enthusiasm to everything I do.
📫Feel free to connect—I’m always excited to discuss innovative ideas or collaborate on cutting-edge research! For further details, please refer to my resume.

Publications
-
No imageScaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent Preprint2026@unpublished{bai2026scalinghorizonnotparameters, title = {Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent}, author = {Bai, Lei and Cao, Zongsheng and Chen, Yang and Cui, Zhiyao and Du, Shangheng and Fan, Yue and Feng, Shiyang and Guo, Zijie and He, Haonan and He, Liang and He, Xiaohan and Hu, Shuyue and Hu, Yusong and Huang, Songtao and Jiang, Yichen and Li, Hao and Li, Xin and Lin, Dahua and Lin, Weihao and Ling, Fenghua and Liu, Dongrui and Liu, Zhuo and Ma, Runmin and Mu, Chunjiang and Peng, Haoyang and Peng, Tianshuo and Shi, Jinxin and Shi, Luohe and Sun, Boyuan and Tan, Zelin and Tang, Shengji and Wang, Qianyi and Wu, Yiming and Xie, Yi and Yan, Xiangchao and Ye, Jingqi and Ye, Peng and Yu, Fangchen and Yuan, Jiakang and Zhan, Bihao and Zhang, Bo and Zhang, Chen and Zhang, Shufei and Zhang, Shuaiyu and Zhang, Wenlong and Zhang, Yiqun and Zhao, Junpeng and Zhong, Zhijie and Zhou, Bowen and Zhou, Yuhao}, year = {2026}, eprint = {2606.30616}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, arxiv = {https://arxiv.org/abs/2606.30616} }We introduce Agents-A1, a 35B Mixture-of-Experts Agentic Model that reaches trillion-parameter-level performance by scaling the agent horizon. We investigate agent-horizon scaling from two perspectives: scaling long-horizon trajectories and scaling heterogeneous agent abilities. To support this goal, we build a long-horizon knowledge-action infrastructure that connects external knowledge, actions, observations, and verifier outcomes, producing agentic trajectories with an average length of 45K tokens. Based on this, we train Agents-A1 with a three-stage recipe. First, we perform full-domain supervised fine-tuning to align the base model with broad agentic behaviors. Second, we train domain-level teacher models to capture specialized expertise in each domain. Third, we propose a multi-teacher domain-routed on-policy distillation with salient vocabulary alignment to improve knowledge transfer efficiency across different domains, unifying six heterogeneous domains into one deployable student model. Agents-A1 achieves strong and broad performance for long-horizon agent benchmarks. Compared with 1T-parameter model such as Kimi-K2.6 and DeepSeek-V4-pro, Agents-A1 achieves leading results on SEAL-0 (56.4), IFBench (80.6), HiPhO (46.4), FrontierScience-Olympiad (79.0), and MolBench-Bind (56.8), and remains highly competitive on SciCode (44.3), HLE (47.6) and BrowseComp (75.5). We hope this work provides the community with a practical path for scaling the horizon using a 35B agent that can reach or match the performance of 1T models on long-horizon tasks.
-
 Findings of the Association for Computational Linguistics: ACL 2026 , 2026@inproceedings{cui2026design, title = {Design First, Code Later: Aesthetically Pleasing Template-Free Slides Generation}, author = {Cui, Zhiyao and Wang, Chenxu and Hu, Shuyue and Zhang, Yiqun and Shao, Wenqi and Zhang, Qiaosheng and Wang, Zhen}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2026}, year = {2026}, arxiv = {https://arxiv.org/abs/2605.26451}, image = {designfirst.png} }
Findings of the Association for Computational Linguistics: ACL 2026 , 2026@inproceedings{cui2026design, title = {Design First, Code Later: Aesthetically Pleasing Template-Free Slides Generation}, author = {Cui, Zhiyao and Wang, Chenxu and Hu, Shuyue and Zhang, Yiqun and Shao, Wenqi and Zhang, Qiaosheng and Wang, Zhen}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2026}, year = {2026}, arxiv = {https://arxiv.org/abs/2605.26451}, image = {designfirst.png} } -
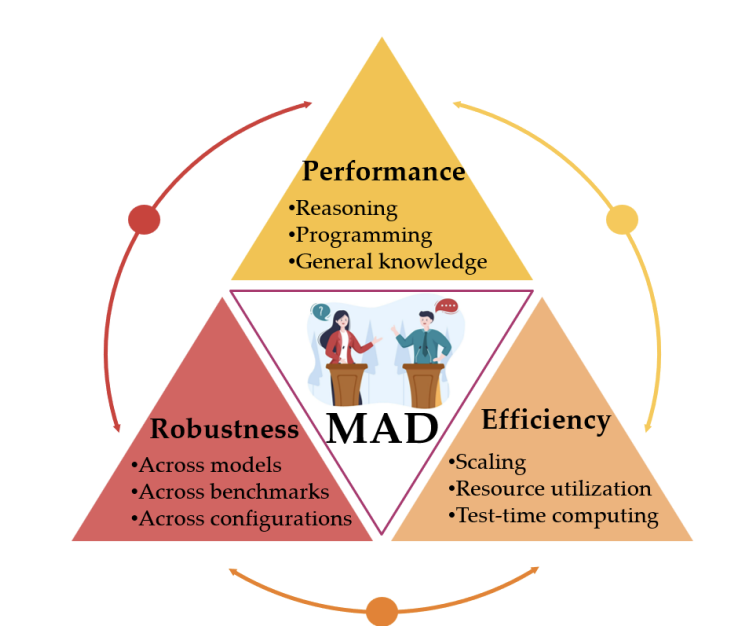 2025@unpublished{zhang2025multiagentdebateanswerquestion, title = {If Multi-Agent Debate is the Answer, What is the Question?}, author = {Zhang, Hangfan and Cui, Zhiyao and Wang, Xinrun and Zhang, Qiaosheng and Wang, Zhen and Wu, Dinghao and Hu, Shuyue}, year = {2025}, eprint = {2502.08788}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, arxiv = {https://arxiv.org/abs/2502.08788}, image = {mad.png} }Multi-agent debate (MAD) has emerged as a promising approach to enhance the factual accuracy and reasoning quality of large language models (LLMs) by engaging multiple agents in iterative discussions during inference. Despite its potential, we argue that current MAD research suffers from critical shortcomings in evaluation practices, including limited dataset overlap and inconsistent baselines, raising significant concerns about generalizability. Correspondingly, this paper presents a systematic evaluation of five representative MAD methods across nine benchmarks using four foundational models. Surprisingly, our findings reveal that MAD methods fail to reliably outperform simple single-agent baselines such as Chain-of-Thought and Self-Consistency, even when consuming additional inference-time computation. From our analysis, we found that model heterogeneity can significantly improve MAD frameworks. We propose Heter-MAD enabling a single LLM agent to access the output from heterogeneous foundation models, which boosts the performance of current MAD frameworks. Finally, we outline potential directions for advancing MAD, aiming to spark a broader conversation and inspire future work in this area.
2025@unpublished{zhang2025multiagentdebateanswerquestion, title = {If Multi-Agent Debate is the Answer, What is the Question?}, author = {Zhang, Hangfan and Cui, Zhiyao and Wang, Xinrun and Zhang, Qiaosheng and Wang, Zhen and Wu, Dinghao and Hu, Shuyue}, year = {2025}, eprint = {2502.08788}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, arxiv = {https://arxiv.org/abs/2502.08788}, image = {mad.png} }Multi-agent debate (MAD) has emerged as a promising approach to enhance the factual accuracy and reasoning quality of large language models (LLMs) by engaging multiple agents in iterative discussions during inference. Despite its potential, we argue that current MAD research suffers from critical shortcomings in evaluation practices, including limited dataset overlap and inconsistent baselines, raising significant concerns about generalizability. Correspondingly, this paper presents a systematic evaluation of five representative MAD methods across nine benchmarks using four foundational models. Surprisingly, our findings reveal that MAD methods fail to reliably outperform simple single-agent baselines such as Chain-of-Thought and Self-Consistency, even when consuming additional inference-time computation. From our analysis, we found that model heterogeneity can significantly improve MAD frameworks. We propose Heter-MAD enabling a single LLM agent to access the output from heterogeneous foundation models, which boosts the performance of current MAD frameworks. Finally, we outline potential directions for advancing MAD, aiming to spark a broader conversation and inspire future work in this area. -
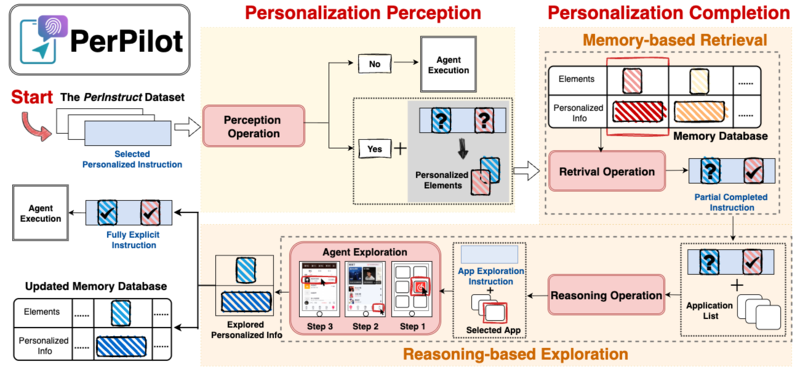 2025@unpublished{wang2025perpilotpersonalizingvlmbasedmobile, title = {PerPilot: Personalizing VLM-based Mobile Agents via Memory and Exploration}, author = {Wang, Xin and Cui, Zhiyao and Li, Hao and Zeng, Ya and Wang, Chenxu and Song, Ruiqi and Chen, Yihang and Shao, Kun and Zhang, Qiaosheng and Liu, Jinzhuo and Ren, Siyue and Hu, Shuyue and Wang, Zhen}, year = {2025}, eprint = {2508.18040}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, arxiv = {https://arxiv.org/abs/2508.18040}, image = {perpilot.png} }Vision language model (VLM)-based mobile agents show great potential for assisting users in performing instruction-driven tasks. However, these agents typically struggle with personalized instructions – those containing ambiguous, user-specific context – a challenge that has been largely overlooked in previous research. In this paper, we define personalized instructions and introduce PerInstruct, a novel human-annotated dataset covering diverse personalized instructions across various mobile scenarios. Furthermore, given the limited personalization capabilities of existing mobile agents, we propose PerPilot, a plug-and-play framework powered by large language models (LLMs) that enables mobile agents to autonomously perceive, understand, and execute personalized user instructions. PerPilot identifies personalized elements and autonomously completes instructions via two complementary approaches: memory-based retrieval and reasoning-based exploration. Experimental results demonstrate that PerPilot effectively handles personalized tasks with minimal user intervention and progressively improves its performance with continued use, underscoring the importance of personalization-aware reasoning for next-generation mobile agents.
2025@unpublished{wang2025perpilotpersonalizingvlmbasedmobile, title = {PerPilot: Personalizing VLM-based Mobile Agents via Memory and Exploration}, author = {Wang, Xin and Cui, Zhiyao and Li, Hao and Zeng, Ya and Wang, Chenxu and Song, Ruiqi and Chen, Yihang and Shao, Kun and Zhang, Qiaosheng and Liu, Jinzhuo and Ren, Siyue and Hu, Shuyue and Wang, Zhen}, year = {2025}, eprint = {2508.18040}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, arxiv = {https://arxiv.org/abs/2508.18040}, image = {perpilot.png} }Vision language model (VLM)-based mobile agents show great potential for assisting users in performing instruction-driven tasks. However, these agents typically struggle with personalized instructions – those containing ambiguous, user-specific context – a challenge that has been largely overlooked in previous research. In this paper, we define personalized instructions and introduce PerInstruct, a novel human-annotated dataset covering diverse personalized instructions across various mobile scenarios. Furthermore, given the limited personalization capabilities of existing mobile agents, we propose PerPilot, a plug-and-play framework powered by large language models (LLMs) that enables mobile agents to autonomously perceive, understand, and execute personalized user instructions. PerPilot identifies personalized elements and autonomously completes instructions via two complementary approaches: memory-based retrieval and reasoning-based exploration. Experimental results demonstrate that PerPilot effectively handles personalized tasks with minimal user intervention and progressively improves its performance with continued use, underscoring the importance of personalization-aware reasoning for next-generation mobile agents. -
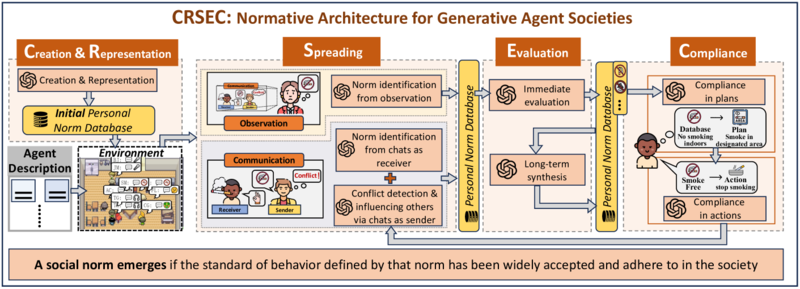 Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24 , 2024@inproceedings{ijcai2024p0874, title = {Emergence of Social Norms in Generative Agent Societies: Principles and Architecture}, author = {Ren, Siyue and Cui, Zhiyao and Song, Ruiqi and Wang, Zhen and Hu, Shuyue}, booktitle = {Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, {IJCAI-24}}, publisher = {International Joint Conferences on Artificial Intelligence Organization}, editor = {Larson, Kate}, pages = {7895--7903}, year = {2024}, month = aug, note = {Human-Centred AI}, doi = {10.24963/ijcai.2024/874}, url = {https://doi.org/10.24963/ijcai.2024/874}, arxiv = {https://arxiv.org/abs/2403.08251}, image = {crsec.png} }Social norms play a crucial role in guiding agents towards understanding and adhering to standards of behavior, thus reducing social conflicts within multi-agent systems (MASs). However, current LLM-based (or generative) MASs lack the capability to be normative. In this paper, we propose a novel architecture, named CRSEC, to empower the emergence of social norms within generative MASs. Our architecture consists of four modules: Creation & Representation, Spreading, Evaluation, and Compliance. This addresses several important aspects of the emergent processes all in one: (i) where social norms come from, (ii) how they are formally represented, (iii) how they spread through agents’ communications and observations, (iv) how they are examined with a sanity check and synthesized in the long term, and (v) how they are incorporated into agents’ planning and actions. Our experiments deployed in the Smallville sandbox game environment demonstrate the capability of our architecture to establish social norms and reduce social conflicts within generative MASs. The positive outcomes of our human evaluation, conducted with 30 evaluators, further affirm the effectiveness of our approach. Our project can be accessed via the following link: https://github.com/sxswz213/CRSEC.
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24 , 2024@inproceedings{ijcai2024p0874, title = {Emergence of Social Norms in Generative Agent Societies: Principles and Architecture}, author = {Ren, Siyue and Cui, Zhiyao and Song, Ruiqi and Wang, Zhen and Hu, Shuyue}, booktitle = {Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, {IJCAI-24}}, publisher = {International Joint Conferences on Artificial Intelligence Organization}, editor = {Larson, Kate}, pages = {7895--7903}, year = {2024}, month = aug, note = {Human-Centred AI}, doi = {10.24963/ijcai.2024/874}, url = {https://doi.org/10.24963/ijcai.2024/874}, arxiv = {https://arxiv.org/abs/2403.08251}, image = {crsec.png} }Social norms play a crucial role in guiding agents towards understanding and adhering to standards of behavior, thus reducing social conflicts within multi-agent systems (MASs). However, current LLM-based (or generative) MASs lack the capability to be normative. In this paper, we propose a novel architecture, named CRSEC, to empower the emergence of social norms within generative MASs. Our architecture consists of four modules: Creation & Representation, Spreading, Evaluation, and Compliance. This addresses several important aspects of the emergent processes all in one: (i) where social norms come from, (ii) how they are formally represented, (iii) how they spread through agents’ communications and observations, (iv) how they are examined with a sanity check and synthesized in the long term, and (v) how they are incorporated into agents’ planning and actions. Our experiments deployed in the Smallville sandbox game environment demonstrate the capability of our architecture to establish social norms and reduce social conflicts within generative MASs. The positive outcomes of our human evaluation, conducted with 30 evaluators, further affirm the effectiveness of our approach. Our project can be accessed via the following link: https://github.com/sxswz213/CRSEC. -
 Journal of Systems Architecture , 2023@article{QI2023102874, title = {TBVPAKE: An efficient and provably secure verifier-based PAKE protocol for IoT applications}, journal = {Journal of Systems Architecture}, volume = {139}, pages = {102874}, year = {2023}, issn = {1383-7621}, doi = {https://doi.org/10.1016/j.sysarc.2023.102874}, url = {https://www.sciencedirect.com/science/article/pii/S138376212300053X}, author = {Qi, Mingping and Cui, Zhiyao and Liang, Gaowei}, image = {tbvpake.png}, keywords = {Password-authenticated key exchange, PAKE, Provably secure, IoT} }Password-authenticated key exchange (PAKE) is an important cryptographic primitive by which two parties are allowed to authenticate each other and establish a cryptographically strong key using a low-entropy password over an insecure channel. Therefore, it is suitable for access control and securing communications between low-cost Internet of Things (IoT) devices where sound security mechanism is difficult to be applied. This paper makes a contribution to securing IoT applications by presenting a secure, efficient and easy-to-implement verifier-based PAKE protocol, named as TBVPAKE (short for Two-Basis Verifier-based PAKE). It is secure against the off-line dictionary attack and server compromise attack, and supports the perfect forward secrecy. Under the widely accepted BPR security model, TBVPAKE is formally proved in this paper in the random oracle model by reducing its security to the Computational Diffie–Hellman (CDH) and Simultaneous Diffie–Hellman (SDH) security assumptions. In addition, we compare the new TBVPAKE with some other outstanding verifier-based PAKE protocols by instantiating them over a commonly used elliptic curve group, and the comparative analysis results definitely show that the new TBVPAKE offers better computational efficiency and ease of implementation. Therefore, the new TBVPAKE might be a better choice for securing IoT applications.
Journal of Systems Architecture , 2023@article{QI2023102874, title = {TBVPAKE: An efficient and provably secure verifier-based PAKE protocol for IoT applications}, journal = {Journal of Systems Architecture}, volume = {139}, pages = {102874}, year = {2023}, issn = {1383-7621}, doi = {https://doi.org/10.1016/j.sysarc.2023.102874}, url = {https://www.sciencedirect.com/science/article/pii/S138376212300053X}, author = {Qi, Mingping and Cui, Zhiyao and Liang, Gaowei}, image = {tbvpake.png}, keywords = {Password-authenticated key exchange, PAKE, Provably secure, IoT} }Password-authenticated key exchange (PAKE) is an important cryptographic primitive by which two parties are allowed to authenticate each other and establish a cryptographically strong key using a low-entropy password over an insecure channel. Therefore, it is suitable for access control and securing communications between low-cost Internet of Things (IoT) devices where sound security mechanism is difficult to be applied. This paper makes a contribution to securing IoT applications by presenting a secure, efficient and easy-to-implement verifier-based PAKE protocol, named as TBVPAKE (short for Two-Basis Verifier-based PAKE). It is secure against the off-line dictionary attack and server compromise attack, and supports the perfect forward secrecy. Under the widely accepted BPR security model, TBVPAKE is formally proved in this paper in the random oracle model by reducing its security to the Computational Diffie–Hellman (CDH) and Simultaneous Diffie–Hellman (SDH) security assumptions. In addition, we compare the new TBVPAKE with some other outstanding verifier-based PAKE protocols by instantiating them over a commonly used elliptic curve group, and the comparative analysis results definitely show that the new TBVPAKE offers better computational efficiency and ease of implementation. Therefore, the new TBVPAKE might be a better choice for securing IoT applications.